Ⓒ 2024- @itatibs
こういうMultiIndexを1次元に戻すTipsはいろんなところで書かれてあると思うんですが、微妙に自分が求めているものと違っていたり、また探すのが面倒なときがあるのでまとめるものです。
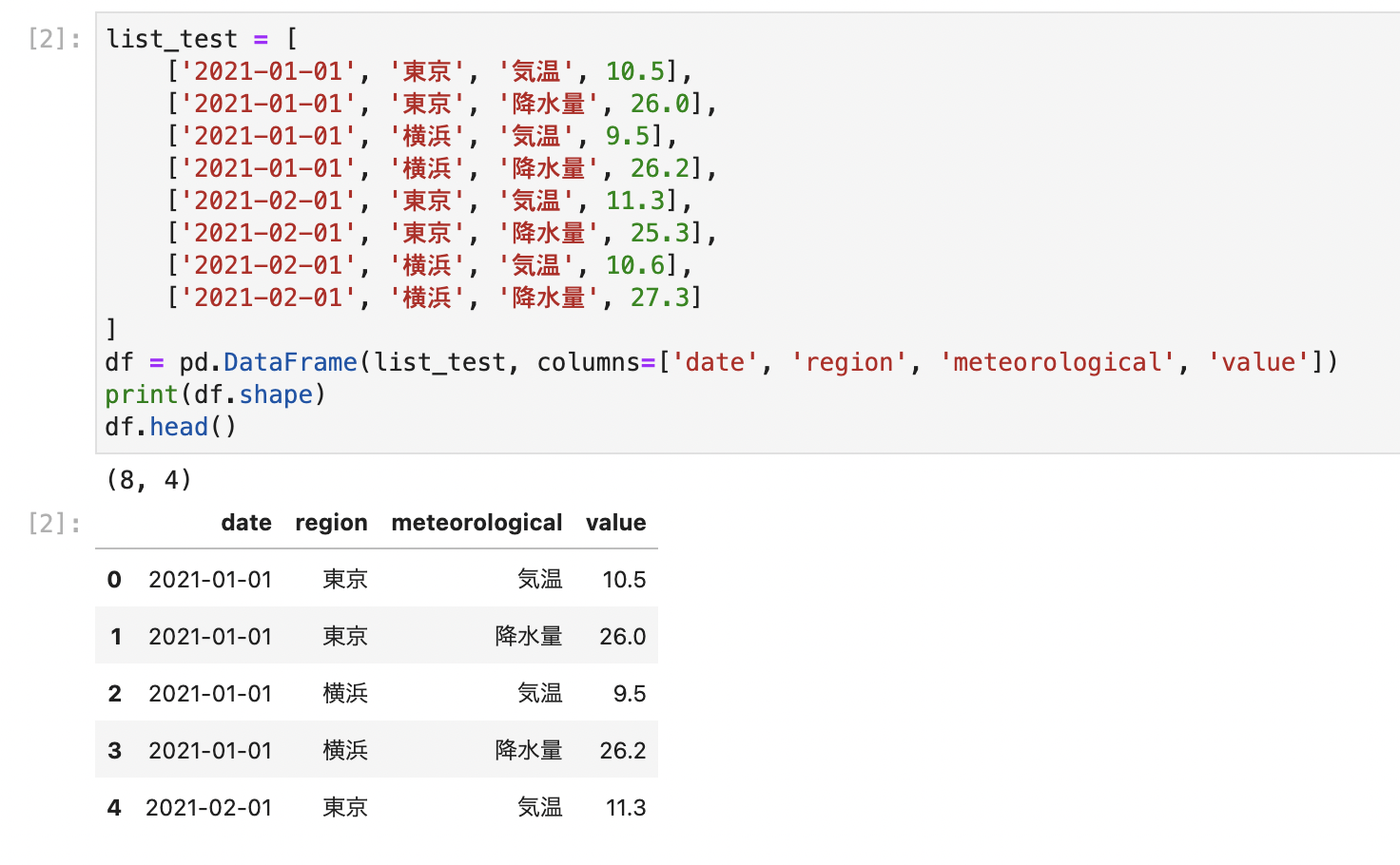
今回の例として、以下のようなサンプルデータを準備します。
list_test = [ ['2021-01-01', '東京', '気温', 10.5], ['2021-01-01', '東京', '降水量', 26.0], ['2021-01-01', '横浜', '気温', 9.5], ['2021-01-01', '横浜', '降水量', 26.2], ['2021-02-01', '東京', '気温', 11.3], ['2021-02-01', '東京', '降水量', 25.3], ['2021-02-01', '横浜', '気温', 10.6], ['2021-02-01', '横浜', '降水量', 27.3] ] df = pd.DataFrame(list_test, columns=['date', 'region', 'meteorological', 'value']) print(df.shape) df.head()
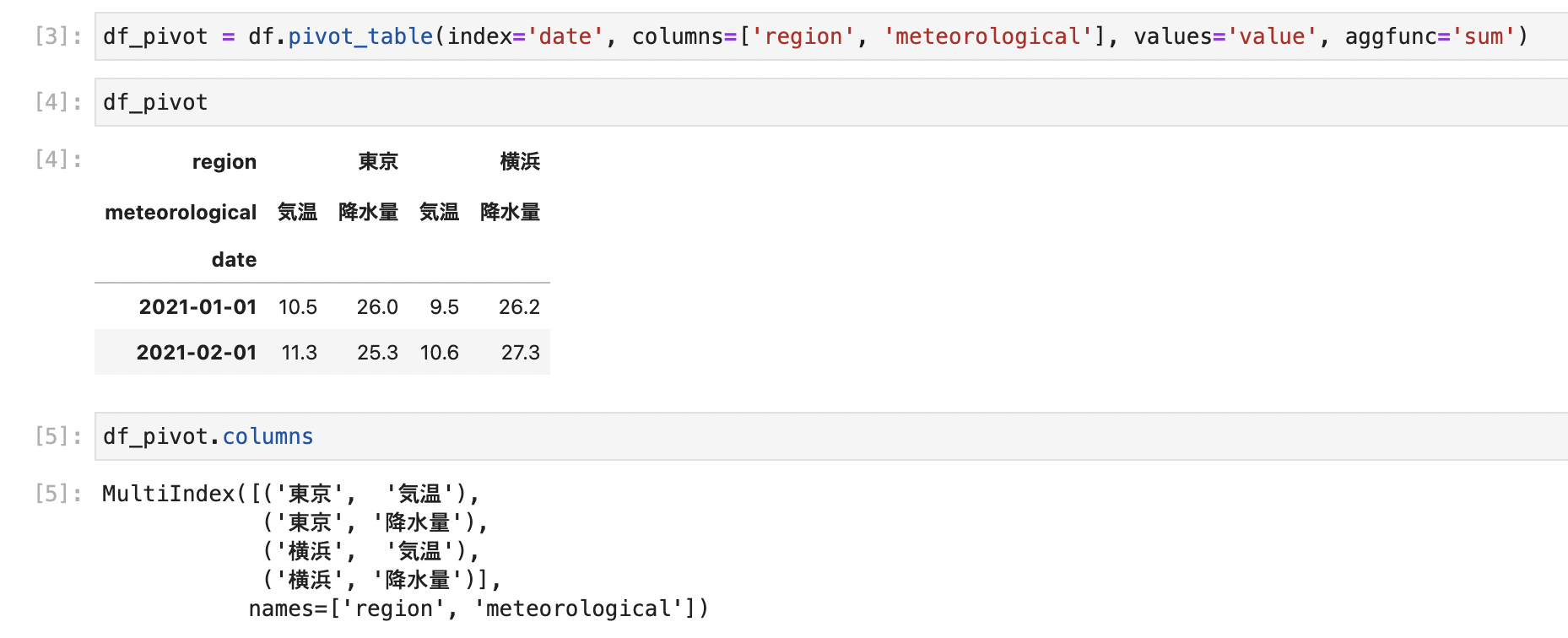
縦持ちになっているデータを複数のカラムを使って横持ちにpivotすると、以下みたいなMultiIndexなカラムができあがります。
df_pivot = df.pivot_table(index='date', columns=['region', 'meteorological'], values='value', aggfunc='sum') df_pivot.columns
pivotとかgroupbyは便利なんですが、気を抜くと軽率にMultiIndexになるので久しぶりにPandas触るとよく面食います。
で、どうやって解決しようかとggってるのを思い出すのですが、解決策ヒットするまでに結構かかるんですよね。
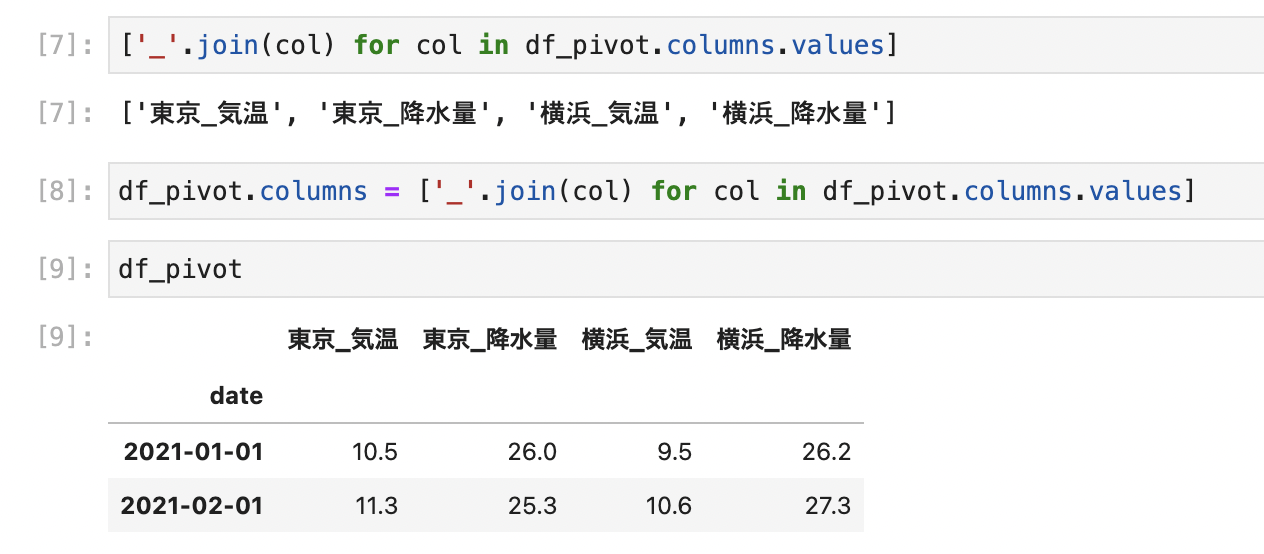
今回の解決策としては、df.columns.valuesとするとtupleの配列を取得することができます。
df_pivot.columns.values

それを配列ごとにjoinしてあげることで、'column1'_'column2'みたいな感じで値を取得することができます。
そのままjoinしようとすると、tupleに対してjoinしようとしてエラーとなるので、今回はfor文を使って1要素ずつjoinするようにしています。
df_pivot.columns = ['_'.join(col) for col in df_pivot.columns.values] df_pivot
今回のサンプルコードについてはこちらのGitHubに載せています。