Ⓒ 2024- @itatibs
PokéAPIというポケモンの各データをRestAPIまたはGraphQLで取得できるすごいAPIがあります。(語彙力)
来年のWCSアナハイムに出場するために(願望)、特にダブルバトルは知識ゲーなので活用できるデータは活用していきたい、ということでこのAPIを使ってデータを取得し、DBに保存してみたいと思います。
毎回PokéAPIを呼び出すというのもできると思いますが、オープンなAPIなので取得するときは最低限に、データは自分の領域に保存して活用することが大事です。
また、将来的にデータを活用したページも作っていきたいのでそういった経緯も含めてDBに保存します。
たいそうなアーキではないですが、以下のような構成でETLを実施しました。

コードはこちらのGithubリポジトリから確認いただけます。
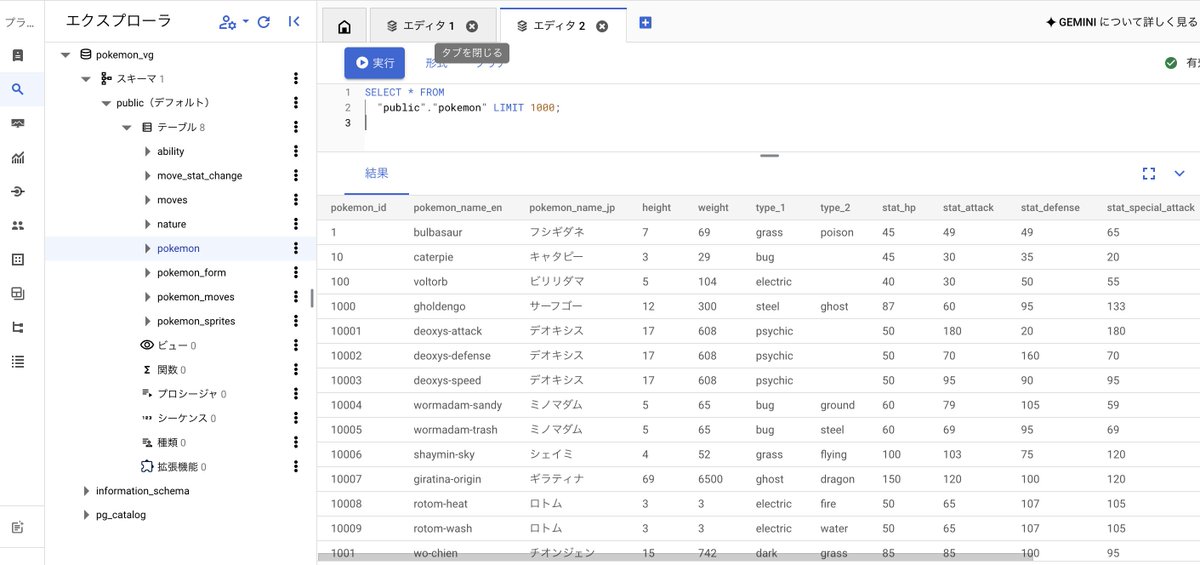
取り込まれたデータはGoogle CloudのCloudSQL for Postgresに保存され、以下のようにブラウザからも確認できます。
見ての通り簡素なアーキでして、最初に検討したときはCICDやクラウドサービスを活用しようと考えていたのですが、個人開発ということで学習コストやクラウドコストを踏まえて 妥協 という名の工夫をいくつかしました。
以下にTipsとしていくつかまとめてご紹介したいと覆います。
クラウドプラットフォームとしてGoogle Cloudを採用しているため、以下をしようと考えていました。
Cloud Composerや、Dataflowを使ってフルマネージドなETLパイプラインを構築するGithub ActionsでCI/CDワークフローを作成して作業の効率化と品質を担保するしかし、開発を進めていく上で以下が課題となりました。
DataflowはどちらかというとTransformに特化したサービスのため今回のサービスからは除外Cloud Composerは実質Airflowだが、ランニングコストが最小でも結構かかることがわかったCloud Composer自体は実は社会人2年目くらいのときに経験があったのですが、だいぶ時間が経っていたのでキャッチアップに時間がかかりそうでしたTerraform、Github Actionsのコードを調べるのにまた、今回取得するPokéAPIのデータは頻繁に何度も取得することはなく、いわゆるワンショットで取れればよいため、妥協してローカルPC上に構築したNotebookにてETLを実施する方針としました。
ちなみに、コード自体は上記のGithubリポジトリにて管理するようにしています。
職業柄、DBは プライベートな環境に置かれていて外部からはアクセスできないようにすべきだ という考えがあり今回のCloudSQL for Postgresについても最初はプライベート通信のみ許可する設定で構築していました。
そのあといざデータをロードするタイミングになって、なかなかDBにアクセスできず。。。
当たり前なのですが、プライベート通信しか許可していないためローカルPCからアクセスできるはずがありません。
プライベートネットワークの中にはGKEがあったのですが、わざわざアクセスするためにVMを立ち上げたりPodを作ったりする気にはならず。。。(踏み台VMを立ち上げるにも東京リージョンは無料枠ないので一定のコストがかかってしまうのも問題でした)
そのため妥協として、今回立ち上げたDBについては外部IPを付与してネットワークからアクセスできるような設定としました。
ただし、セキュリティを確保するためにCloud SQL Auth Proxyを設定してIPを指定することなく、サービスアカウントのIAMによってアクセスできるように設計しています。
CloudSQL for Postgresのスキーマ管理について、当初は業務でも利用していたLiquibaseを採用しようと考えていました。
しかし、経験上管理と運用が煩雑だったので、もっと楽に管理できるツールを探していたところ、sqldefのpsqldefがスキーマ管理に特化していてLiquibaseよりも簡単に管理できそうだったので、こちらを利用してみることにしました。
こちらについてはCI/CDワークフローによって自動適用できるように開発しており、こちらのGithubリポジトリより開発内容をご確認いただけます。
Liquibaseより楽と感じたのは、ALTERコマンド文が不要で全てCREATE TABLEコマンド文にて定義することが可能で、PRIMARY KEYやカラムに変更があった場合も自動で変更差分を検知してpsqldef側でALTERコマンドを作成して適用してくれる点です。
ただし、sqldefはあくまでスキーマ管理のみのため、例えばFUNCTIONなどのトリガー関数は設定できない(Issuesには要望として上がっているようです)ので利用できる項目についてはREADMEにて事前に確認するのが良いかなと思います。
ここまで色々やってAPIからデータを取得してDBに保存することができたのですが、着想としては 「APIの元となっているデータだけ取れれば楽なのにな」 でした。
最初に調べた時は見つからなかったので、APIからETLするようにしたのですが、、、
ここにAPI呼び出しの元となるcsvファイルの一覧がありました。
Githubにあるので、ドメインをhttps://raw.githubusercontent.com/に変更するだけで取得できます。
ただし、細かく正規化されているためいくつかのファイルを組み合わせる必要がありデータ分析の前処理にありがちな 正規化を解く 作業が必要となってくるのでそれであれば提供されたAPIから取った方が楽かなと思いました。
※もちろんDBで厳密に管理したい場合は正規化されたCSVファイルから直接取り込むのが良いのかなと思います。